Data Mining: Classification & Clustering
Classification using Decision Tree, KNN, SVM, & Random Forest with PCA for Maternal Health Risk Dataset and Parkinson’s Disease.
Clustering using Lloyd’sk-means, FuzzyC-means, and DBSCAN on a dataset of points on a 2d plane. The Elbow method used to find the optimal number of clusters. (Github)
Classification: Maternal Health Risk
Dataset Information
The dataset used in this project contains information related to maternal health risks, including features such as age, blood pressure, blood sugar, body temperature, and heart rate. The target variable is the risk level, which has been encoded numerically.
Summary of Results
RandomForest: 84%
KNeighbors: 85%
SVM: 68%
DecisionTree: 87%
Classification: Parkinson’s Disease Detection
Dataset Information
In this project, we use a dataset containing various voice features to build and evaluate machine learning models for PD classification. This Dataset contains 754 different features.
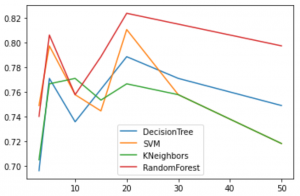
Summary of Results
For Different feature extraction parameter for PCA algorithm, here is the result:
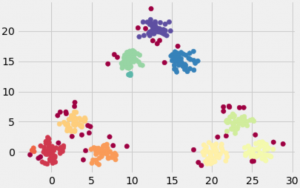
Clustering: 2D data points
Here is DBSCAN result. See notebook for more detail and other results.